LeetCode 题解工作台
从前序与中序遍历序列构造二叉树
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的 先序遍历 , inorder 是同一棵树的 中序遍历 ,请构造二叉树并返回其根节点。 示例 1: 输入 : preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]…
5
题型
7
代码语言
3
相关题
当前训练重点
中等 · 数组·哈希·扫描
答案摘要
前序序列的第一个节点 为根节点,我们在中序序列中找到根节点的位置 ,可以将中序序列划分为左子树 、右子树 。 通过左右子树的区间,可以计算出左、右子树节点的个数,假设为 和 。然后在前序节点中,从根节点往后的 个节点为左子树,再往后的 个节点为右子树。
Interview AiBoxInterview AiBox 实时 AI 助手,陪你讲清 数组·哈希·扫描 题型思路
题目描述
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
示例 1:
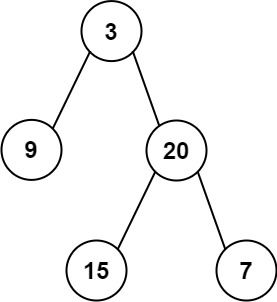
输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7] 输出: [3,9,20,null,null,15,7]
示例 2:
输入: preorder = [-1], inorder = [-1] 输出: [-1]
提示:
1 <= preorder.length <= 3000inorder.length == preorder.length-3000 <= preorder[i], inorder[i] <= 3000preorder和inorder均 无重复 元素inorder均出现在preorderpreorder保证 为二叉树的前序遍历序列inorder保证 为二叉树的中序遍历序列
解题思路
方法一:哈希表 + 递归
前序序列的第一个节点 为根节点,我们在中序序列中找到根节点的位置 ,可以将中序序列划分为左子树 、右子树 。
通过左右子树的区间,可以计算出左、右子树节点的个数,假设为 和 。然后在前序节点中,从根节点往后的 个节点为左子树,再往后的 个节点为右子树。
因此,我们设计一个函数 ,其中 和 分别表示前序序列和中序序列的起始位置,而 表示节点个数。函数的返回值是以 为前序序列,以 为中序序列构造出的二叉树。
函数 的执行过程如下:
- 如果 ,说明没有节点,返回空节点。
- 取出前序序列的第一个节点 作为根节点,然后利用哈希表 找到根节点在中序序列中的位置 ,那么左子树的节点个数为 ,右子树的节点个数为 。
- 递归构造左子树 和右子树 。
- 最后返回以 为根节点且左右子树分别为 和 的二叉树。
时间复杂度 ,空间复杂度 。其中 为二叉树节点个数。
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def buildTree(self, preorder: List[int], inorder: List[int]) -> Optional[TreeNode]:
def dfs(i: int, j: int, n: int) -> Optional[TreeNode]:
if n <= 0:
return None
v = preorder[i]
k = d[v]
l = dfs(i + 1, j, k - j)
r = dfs(i + 1 + k - j, k + 1, n - k + j - 1)
return TreeNode(v, l, r)
d = {v: i for i, v in enumerate(inorder)}
return dfs(0, 0, len(preorder))
如果题目中给定的节点值存在重复,那么我们只需要记录每个节点值出现的所有位置,然后递归构建出所有可能的二叉树即可。
class Solution:
def getBinaryTrees(self, preOrder: List[int], inOrder: List[int]) -> List[TreeNode]:
def dfs(i: int, j: int, n: int) -> List[TreeNode]:
if n <= 0:
return [None]
v = preOrder[i]
ans = []
for k in d[v]:
if j <= k < j + n:
for l in dfs(i + 1, j, k - j):
for r in dfs(i + 1 + k - j, k + 1, n - 1 - (k - j)):
ans.append(TreeNode(v, l, r))
return ans
d = defaultdict(list)
for i, x in enumerate(inOrder):
d[x].append(i)
return dfs(0, 0, len(preOrder))
复杂度分析
| 指标 | 值 |
|---|---|
| 时间 | Depends on the final approach |
| 空间 | Depends on the final approach |
面试官常问的追问
外企场景- question_mark
Do you understand how to scan the preorder array and use the inorder array to identify subtree structures?
- question_mark
Can you explain how the hash table optimizes the process of finding the root's index in inorder?
- question_mark
Will you handle edge cases like when the tree is very small (1 or 2 nodes)?
常见陷阱
外企场景- error
Failing to efficiently look up the index of nodes in the inorder array without a hash table can lead to suboptimal solutions.
- error
Not correctly handling the boundary conditions when recursively dividing the preorder and inorder arrays for smaller subtrees.
- error
Assuming the tree always has a specific shape or depth, which could lead to incorrect handling of unbalanced trees.
进阶变体
外企场景- arrow_right_alt
Construct Binary Tree from Preorder and Postorder Traversal
- arrow_right_alt
Construct Binary Search Tree from Preorder Traversal
- arrow_right_alt
Construct Binary Tree from Level Order and Inorder Traversal