LeetCode 题解工作台
从中序与后序遍历序列构造二叉树
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。 示例 1: 输入: inorder = [9,3,15,20,7], postorder = [9,15,7,20,3] …
5
题型
6
代码语言
3
相关题
当前训练重点
中等 · 数组·哈希·扫描
答案摘要
后序遍历的最后一个节点是根节点,我们可以根据这个特点找到根节点在中序遍历中的位置,然后递归地构造左右子树。 具体地,我们先用一个哈希表 存储中序遍历中每个节点的位置。然后我们设计一个递归函数 $dfs(i, j, n)$,其中 和 分别表示中序遍历和后序遍历的起点,而 表示子树包含的节点数。函数的逻辑如下:
Interview AiBoxInterview AiBox 实时 AI 助手,陪你讲清 数组·哈希·扫描 题型思路
题目描述
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
示例 1:
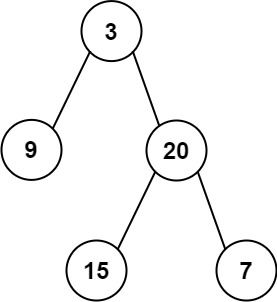
输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3] 输出:[3,9,20,null,null,15,7]
示例 2:
输入:inorder = [-1], postorder = [-1] 输出:[-1]
提示:
1 <= inorder.length <= 3000postorder.length == inorder.length-3000 <= inorder[i], postorder[i] <= 3000inorder和postorder都由 不同 的值组成postorder中每一个值都在inorder中inorder保证是树的中序遍历postorder保证是树的后序遍历
解题思路
方法一:哈希表 + 递归
后序遍历的最后一个节点是根节点,我们可以根据这个特点找到根节点在中序遍历中的位置,然后递归地构造左右子树。
具体地,我们先用一个哈希表 存储中序遍历中每个节点的位置。然后我们设计一个递归函数 ,其中 和 分别表示中序遍历和后序遍历的起点,而 表示子树包含的节点数。函数的逻辑如下:
- 如果 ,说明子树为空,返回空节点。
- 否则,取出后序遍历的最后一个节点 ,然后我们在哈希表 中找到 在中序遍历中的位置,设为 。那么左子树包含的节点数为 ,右子树包含的节点数为 。
- 递归构造左子树 和右子树 ,并连接到根节点上,最后返回根节点。
时间复杂度 ,空间复杂度 。其中 是二叉树的节点个数。
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def buildTree(self, inorder: List[int], postorder: List[int]) -> Optional[TreeNode]:
def dfs(i: int, j: int, n: int) -> Optional[TreeNode]:
if n <= 0:
return None
v = postorder[j + n - 1]
k = d[v]
l = dfs(i, j, k - i)
r = dfs(k + 1, j + k - i, n - k + i - 1)
return TreeNode(v, l, r)
d = {v: i for i, v in enumerate(inorder)}
return dfs(0, 0, len(inorder))
复杂度分析
| 指标 | 值 |
|---|---|
| 时间 | complexity is O(n) since each node is visited once and hash lookups are O(1), while space complexity is O(h) for recursion stack, where h is tree height. Array scanning without slicing and using hash mapping guarantees linear time and controlled space proportional to tree depth. |
| 空间 | Depends on the final approach |
面试官常问的追问
外企场景- question_mark
Do you identify the root in postorder before splitting inorder?
- question_mark
Can you track subtree indices without creating new arrays to reduce space usage?
- question_mark
Will you handle null subtrees correctly to avoid misalignments in recursion?
常见陷阱
外企场景- error
Re-scanning inorder in each recursion leading to O(n^2) time complexity.
- error
Incorrectly calculating left and right subtree sizes causing wrong tree structure.
- error
Not handling base cases for empty subtrees resulting in runtime errors.
进阶变体
外企场景- arrow_right_alt
Construct Binary Tree from Preorder and Inorder Traversal
- arrow_right_alt
Construct Binary Search Tree from Preorder Traversal
- arrow_right_alt
Validate Binary Tree from Inorder and Postorder Traversals