LeetCode 题解工作台
矩阵转换后的排名
给你一个 m x n 的矩阵 matrix ,请你返回一个新的矩阵 answer ,其中 answer[row][col] 是 matrix[row][col] 的排名。 每个元素的 排名 是一个整数,表示这个元素相对于其他元素的大小关系,它按照如下规则计算: 排名是从 1 开始的一个整数。 如果两…
6
题型
4
代码语言
3
相关题
当前训练重点
困难 · 并查集
答案摘要
我们先考虑简化情形:没有相同的元素。那么显然最小的元素的秩为 ,第二小的元素则要考虑是否和最小元素同行或同列。于是得到贪心解法:从小到大遍历元素,并维护每行、每列的最大秩,该元素的秩即为同行、同列的最大秩加 。见题目:[2371. 最小化网格中的最大值](https://github.com/doocs/leetcode/blob/main/solution/2300-2399/2371.Mini…
Interview AiBoxInterview AiBox 实时 AI 助手,陪你讲清 并查集 题型思路
题目描述
给你一个 m x n 的矩阵 matrix ,请你返回一个新的矩阵 answer ,其中 answer[row][col] 是 matrix[row][col] 的排名。
每个元素的 排名 是一个整数,表示这个元素相对于其他元素的大小关系,它按照如下规则计算:
- 排名是从 1 开始的一个整数。
- 如果两个元素
p和q在 同一行 或者 同一列 ,那么:- 如果
p < q,那么rank(p) < rank(q) - 如果
p == q,那么rank(p) == rank(q) - 如果
p > q,那么rank(p) > rank(q)
- 如果
- 排名 需要越 小 越好。
题目保证按照上面规则 answer 数组是唯一的。
示例 1:
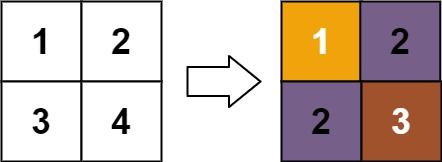
输入:matrix = [[1,2],[3,4]] 输出:[[1,2],[2,3]] 解释: matrix[0][0] 的排名为 1 ,因为它是所在行和列的最小整数。 matrix[0][1] 的排名为 2 ,因为 matrix[0][1] > matrix[0][0] 且 matrix[0][0] 的排名为 1 。 matrix[1][0] 的排名为 2 ,因为 matrix[1][0] > matrix[0][0] 且 matrix[0][0] 的排名为 1 。 matrix[1][1] 的排名为 3 ,因为 matrix[1][1] > matrix[0][1], matrix[1][1] > matrix[1][0] 且 matrix[0][1] 和 matrix[1][0] 的排名都为 2 。
示例 2:
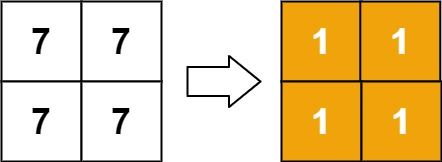
输入:matrix = [[7,7],[7,7]] 输出:[[1,1],[1,1]]
示例 3:
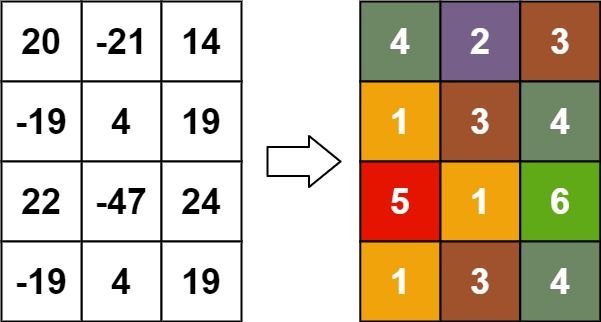
输入:matrix = [[20,-21,14],[-19,4,19],[22,-47,24],[-19,4,19]] 输出:[[4,2,3],[1,3,4],[5,1,6],[1,3,4]]
提示:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 500-109 <= matrix[row][col] <= 109
解题思路
方法一:排序 + 并查集
我们先考虑简化情形:没有相同的元素。那么显然最小的元素的秩为 ,第二小的元素则要考虑是否和最小元素同行或同列。于是得到贪心解法:从小到大遍历元素,并维护每行、每列的最大秩,该元素的秩即为同行、同列的最大秩加 。见题目:2371. 最小化网格中的最大值。
存在相同元素时则较为复杂,假设两个相同元素同行(或同列),那么就要考虑到两个元素分别对应的行(或列)的最大秩。同时还可能出现联动,比如元素 a 和 b 同行,b 和 c 同列,那么要同时考虑这三个元素。
这种联动容易想到并查集,于是我们用并查集将元素分为几个连通块,对于每个连通块,里面所有元素对应的行或列的最大秩加 ,即为该连通块内所有元素的秩。
时间复杂度 ,空间复杂度 。其中 和 分别为矩阵的行数和列数。
class UnionFind:
def __init__(self, n):
self.p = list(range(n))
self.size = [1] * n
def find(self, x):
if self.p[x] != x:
self.p[x] = self.find(self.p[x])
return self.p[x]
def union(self, a, b):
pa, pb = self.find(a), self.find(b)
if pa != pb:
if self.size[pa] > self.size[pb]:
self.p[pb] = pa
self.size[pa] += self.size[pb]
else:
self.p[pa] = pb
self.size[pb] += self.size[pa]
def reset(self, x):
self.p[x] = x
self.size[x] = 1
class Solution:
def matrixRankTransform(self, matrix: List[List[int]]) -> List[List[int]]:
m, n = len(matrix), len(matrix[0])
d = defaultdict(list)
for i, row in enumerate(matrix):
for j, v in enumerate(row):
d[v].append((i, j))
row_max = [0] * m
col_max = [0] * n
ans = [[0] * n for _ in range(m)]
uf = UnionFind(m + n)
for v in sorted(d):
rank = defaultdict(int)
for i, j in d[v]:
uf.union(i, j + m)
for i, j in d[v]:
rank[uf.find(i)] = max(rank[uf.find(i)], row_max[i], col_max[j])
for i, j in d[v]:
ans[i][j] = row_max[i] = col_max[j] = 1 + rank[uf.find(i)]
for i, j in d[v]:
uf.reset(i)
uf.reset(j + m)
return ans
复杂度分析
| 指标 | 值 |
|---|---|
| 时间 | complexity is dominated by sorting cells O(m _n_ log(m _n)) and graph processing. Space complexity depends on storing parent arrays for Union Find and adjacency lists for topological sorting, typically O(m_ n). |
| 空间 | Depends on the final approach |
面试官常问的追问
外企场景- question_mark
Watch for correctly linking equal elements to avoid rank conflicts.
- question_mark
Check for proper graph edge creation between dependent elements in rows and columns.
- question_mark
Ensure topological sort respects both row and column ordering constraints to maintain uniqueness.
常见陷阱
外企场景- error
Failing to merge equal elements before building dependencies, causing incorrect rank assignments.
- error
Ignoring column or row constraints when adding graph edges, leading to invalid topological ordering.
- error
Assuming ranks can be assigned greedily without topological sorting, which breaks uniqueness in some matrices.
进阶变体
外企场景- arrow_right_alt
Apply the same approach to a 1D array to assign relative ranks respecting duplicates.
- arrow_right_alt
Compute ranks only for a single row or column subset while maintaining graph indegree ordering.
- arrow_right_alt
Use the algorithm for sparse matrices where most entries are zero, optimizing Union Find and graph storage.