LeetCode 题解工作台
检查边长度限制的路径是否存在
给你一个 n 个点组成的无向图边集 edgeList ,其中 edgeList[i] = [u i , v i , dis i ] 表示点 u i 和点 v i 之间有一条长度为 dis i 的边。请注意,两个点之间可能有 超过一条边 。 给你一个查询数组 queries ,其中 queries[j…
5
题型
5
代码语言
3
相关题
当前训练重点
困难 · 双·指针·invariant
答案摘要
根据题目要求,我们需要对每个查询 进行判断,即判断当前查询的两个点 和 之间是否存在一条边权小于等于 的路径。 判断两点是否连通可以通过并查集来实现。另外,由于查询的顺序对结果没有影响,因此我们可以先将所有查询按照 从小到大排序,所有边也按照边权从小到大排序。
Interview AiBoxInterview AiBox 实时 AI 助手,陪你讲清 双·指针·invariant 题型思路
题目描述
给你一个 n 个点组成的无向图边集 edgeList ,其中 edgeList[i] = [ui, vi, disi] 表示点 ui 和点 vi 之间有一条长度为 disi 的边。请注意,两个点之间可能有 超过一条边 。
给你一个查询数组queries ,其中 queries[j] = [pj, qj, limitj] ,你的任务是对于每个查询 queries[j] ,判断是否存在从 pj 到 qj 的路径,且这条路径上的每一条边都 严格小于 limitj 。
请你返回一个 布尔数组 answer ,其中 answer.length == queries.length ,当 queries[j] 的查询结果为 true 时, answer 第 j 个值为 true ,否则为 false 。
示例 1:
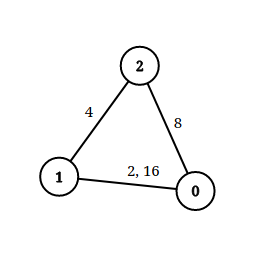
输入:n = 3, edgeList = [[0,1,2],[1,2,4],[2,0,8],[1,0,16]], queries = [[0,1,2],[0,2,5]] 输出:[false,true] 解释:上图为给定的输入数据。注意到 0 和 1 之间有两条重边,分别为 2 和 16 。 对于第一个查询,0 和 1 之间没有小于 2 的边,所以我们返回 false 。 对于第二个查询,有一条路径(0 -> 1 -> 2)两条边都小于 5 ,所以这个查询我们返回 true 。
示例 2:
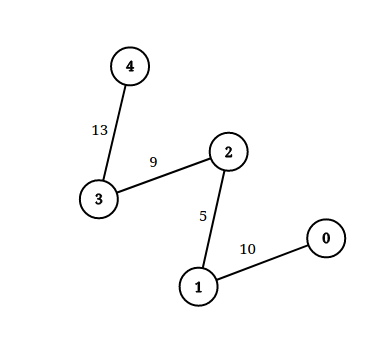
输入:n = 5, edgeList = [[0,1,10],[1,2,5],[2,3,9],[3,4,13]], queries = [[0,4,14],[1,4,13]] 输出:[true,false] 解释:上图为给定数据。
提示:
2 <= n <= 1051 <= edgeList.length, queries.length <= 105edgeList[i].length == 3queries[j].length == 30 <= ui, vi, pj, qj <= n - 1ui != vipj != qj1 <= disi, limitj <= 109- 两个点之间可能有 多条 边。
解题思路
方法一:离线查询 + 并查集
根据题目要求,我们需要对每个查询 进行判断,即判断当前查询的两个点 和 之间是否存在一条边权小于等于 的路径。
判断两点是否连通可以通过并查集来实现。另外,由于查询的顺序对结果没有影响,因此我们可以先将所有查询按照 从小到大排序,所有边也按照边权从小到大排序。
然后对于每个查询,我们从边权最小的边开始,将边权严格小于 的所有边加入并查集,接着利用并查集的查询操作判断两点是否连通即可。
时间复杂度 ,其中 和 分别为边数和查询数。
class Solution:
def distanceLimitedPathsExist(
self, n: int, edgeList: List[List[int]], queries: List[List[int]]
) -> List[bool]:
def find(x):
if p[x] != x:
p[x] = find(p[x])
return p[x]
p = list(range(n))
edgeList.sort(key=lambda x: x[2])
j = 0
ans = [False] * len(queries)
for i, (a, b, limit) in sorted(enumerate(queries), key=lambda x: x[1][2]):
while j < len(edgeList) and edgeList[j][2] < limit:
u, v, _ = edgeList[j]
p[find(u)] = find(v)
j += 1
ans[i] = find(a) == find(b)
return ans
附并查集相关介绍以及常用模板:
并查集是一种树形的数据结构,顾名思义,它用于处理一些不交集的合并及查询问题。 它支持两种操作:
- 查找(Find):确定某个元素处于哪个子集,单次操作时间复杂度
- 合并(Union):将两个子集合并成一个集合,单次操作时间复杂度
其中 为阿克曼函数的反函数,其增长极其缓慢,也就是说其单次操作的平均运行时间可以认为是一个很小的常数。
以下是并查集的常用模板,需要熟练掌握。其中:
n表示节点数p存储每个点的父节点,初始时每个点的父节点都是自己size只有当节点是祖宗节点时才有意义,表示祖宗节点所在集合中,点的数量find(x)函数用于查找 所在集合的祖宗节点union(a, b)函数用于合并 和 所在的集合
p = list(range(n))
size = [1] * n
def find(x):
if p[x] != x:
# 路径压缩
p[x] = find(p[x])
return p[x]
def union(a, b):
pa, pb = find(a), find(b)
if pa == pb:
return
p[pa] = pb
size[pb] += size[pa]
复杂度分析
| 指标 | 值 |
|---|---|
| 时间 | Depends on the final approach |
| 空间 | Depends on the final approach |
面试官常问的追问
外企场景- question_mark
Check the candidate's ability to optimize repeated computations across multiple queries.
- question_mark
Look for a solid understanding of union-find and graph traversal algorithms.
- question_mark
Assess how efficiently the candidate integrates sorting and two-pointer techniques into their solution.
常见陷阱
外企场景- error
Failing to optimize for multiple queries by not sorting or reordering them properly.
- error
Mismanaging the union-find data structure, leading to unnecessary recomputation of connected components.
- error
Overcomplicating the solution by attempting brute force for each query without leveraging sorted edges.
进阶变体
外企场景- arrow_right_alt
Implementing the solution with a depth-first search (DFS) approach instead of union-find.
- arrow_right_alt
Handling cases where the edge distances are extremely large, and the graph is sparse.
- arrow_right_alt
Optimizing for very large graphs with a focus on minimizing space complexity.