LeetCode 题解工作台
获取你好友已观看的视频
有 n 个人,每个人都有一个 0 到 n-1 的唯一 id 。 给你数组 watchedVideos 和 friends ,其中 watchedVideos[i] 和 friends[i] 分别表示 id = i 的人观看过的视频列表和他的好友列表。 Level 1 的视频包含所有你好友观看过的视频…
5
题型
5
代码语言
3
相关题
当前训练重点
中等 · 数组·哈希·扫描
答案摘要
我们可以使用广度优先搜索的方法,从 出发,找到所有距离为 的好友,然后统计这些好友观看的视频。 具体地,我们可以使用一个队列 来存储当前层的好友,初始时将 加入队列 中,用一个哈希表或者布尔数组 来记录已经访问过的好友,然后进行 次循环,每次循环将队列中的所有好友出队,并将他们的好友加入队列,直到找到所有距禒为 的好友。
Interview AiBoxInterview AiBox 实时 AI 助手,陪你讲清 数组·哈希·扫描 题型思路
题目描述
有 n 个人,每个人都有一个 0 到 n-1 的唯一 id 。
给你数组 watchedVideos 和 friends ,其中 watchedVideos[i] 和 friends[i] 分别表示 id = i 的人观看过的视频列表和他的好友列表。
Level 1 的视频包含所有你好友观看过的视频,level 2 的视频包含所有你好友的好友观看过的视频,以此类推。一般的,Level 为 k 的视频包含所有从你出发,最短距离为 k 的好友观看过的视频。
给定你的 id 和一个 level 值,请你找出所有指定 level 的视频,并将它们按观看频率升序返回。如果有频率相同的视频,请将它们按字母顺序从小到大排列。
示例 1:
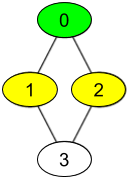
输入:watchedVideos = [["A","B"],["C"],["B","C"],["D"]], friends = [[1,2],[0,3],[0,3],[1,2]], id = 0, level = 1 输出:["B","C"] 解释: 你的 id 为 0(绿色),你的朋友包括(黄色): id 为 1 -> watchedVideos = ["C"] id 为 2 -> watchedVideos = ["B","C"] 你朋友观看过视频的频率为: B -> 1 C -> 2
示例 2:
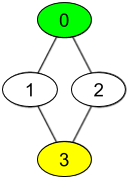
输入:watchedVideos = [["A","B"],["C"],["B","C"],["D"]], friends = [[1,2],[0,3],[0,3],[1,2]], id = 0, level = 2 输出:["D"] 解释: 你的 id 为 0(绿色),你朋友的朋友只有一个人,他的 id 为 3(黄色)。
提示:
n == watchedVideos.length == friends.length2 <= n <= 1001 <= watchedVideos[i].length <= 1001 <= watchedVideos[i][j].length <= 80 <= friends[i].length < n0 <= friends[i][j] < n0 <= id < n1 <= level < n- 如果
friends[i]包含j,那么friends[j]包含i
解题思路
方法一:BFS
我们可以使用广度优先搜索的方法,从 出发,找到所有距离为 的好友,然后统计这些好友观看的视频。
具体地,我们可以使用一个队列 来存储当前层的好友,初始时将 加入队列 中,用一个哈希表或者布尔数组 来记录已经访问过的好友,然后进行 次循环,每次循环将队列中的所有好友出队,并将他们的好友加入队列,直到找到所有距禒为 的好友。
然后,我们使用一个哈希表 来统计这些好友观看的视频及其频率,最后将哈希表中的键值对按照频率升序排序,如果频率相同,则按照视频名称升序排序。最后返回排序后的视频名称列表。
时间复杂度 ,空间复杂度 。其中 和 分别是数组 和 的长度,而 是所有好友观看的视频数量。
class Solution:
def watchedVideosByFriends(
self,
watchedVideos: List[List[str]],
friends: List[List[int]],
id: int,
level: int,
) -> List[str]:
q = deque([id])
vis = {id}
for _ in range(level):
for _ in range(len(q)):
i = q.popleft()
for j in friends[i]:
if j not in vis:
vis.add(j)
q.append(j)
cnt = Counter()
for i in q:
for v in watchedVideos[i]:
cnt[v] += 1
return sorted(cnt.keys(), key=lambda k: (cnt[k], k))
复杂度分析
| 指标 | 值 |
|---|---|
| 时间 | complexity is O(n * m), where n is the number of people and m is the average number of videos watched by each person. BFS takes O(n) time, and counting frequencies and sorting the videos takes additional time proportional to the number of videos. |
| 空间 | Depends on the final approach |
面试官常问的追问
外企场景- question_mark
Strong understanding of graph traversal algorithms like BFS is demonstrated.
- question_mark
Clear understanding of hash tables to track video frequencies.
- question_mark
Proper implementation of sorting with multiple criteria (frequency, then lexicographically).
常见陷阱
外企场景- error
Misunderstanding the BFS algorithm and incorrectly calculating the level of friends.
- error
Failing to correctly count the frequency of videos watched by friends at the right level.
- error
Not sorting the videos in both frequency order and lexicographically for ties.
进阶变体
外企场景- arrow_right_alt
Find videos watched by friends up to a different level (e.g., level 3).
- arrow_right_alt
Return the result sorted by different criteria, such as descending frequency.
- arrow_right_alt
Optimize the solution for larger inputs, handling the constraints more efficiently.