LeetCode 题解工作台
单词搜索 II
给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words , 返回所有二维网格上的单词 。 单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。 示例 1: 输入: …
5
题型
5
代码语言
3
相关题
当前训练重点
困难 · 回溯·pruning
答案摘要
我们首先将 `words` 中的单词构建成前缀树,前缀树的每个节点包含一个长度为 的数组 `children`,表示该节点的子节点,数组的下标表示子节点对应的字符,数组的值表示子节点的引用。同时,每个节点还包含一个整数 `ref`,表示该节点对应的单词在 `words` 中的引用,如果该节点不是单词的结尾,则 `ref` 的值为 。 接下来,我们对于 `board` 中的每个单元格,从该单元格出…
Interview AiBoxInterview AiBox 实时 AI 助手,陪你讲清 回溯·pruning 题型思路
题目描述
给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words, 返回所有二维网格上的单词 。
单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
示例 1:
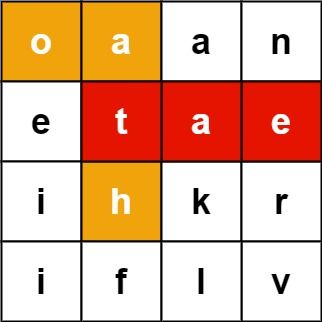
输入:board = [["o","a","a","n"],["e","t","a","e"],["i","h","k","r"],["i","f","l","v"]], words = ["oath","pea","eat","rain"] 输出:["eat","oath"]
示例 2:
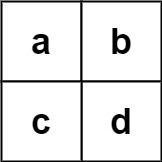
输入:board = [["a","b"],["c","d"]], words = ["abcb"] 输出:[]
提示:
m == board.lengthn == board[i].length1 <= m, n <= 12board[i][j]是一个小写英文字母1 <= words.length <= 3 * 1041 <= words[i].length <= 10words[i]由小写英文字母组成words中的所有字符串互不相同
解题思路
方法一:前缀树 + DFS
我们首先将 words 中的单词构建成前缀树,前缀树的每个节点包含一个长度为 的数组 children,表示该节点的子节点,数组的下标表示子节点对应的字符,数组的值表示子节点的引用。同时,每个节点还包含一个整数 ref,表示该节点对应的单词在 words 中的引用,如果该节点不是单词的结尾,则 ref 的值为 。
接下来,我们对于 board 中的每个单元格,从该单元格出发,进行深度优先搜索,搜索过程中,如果当前单词不是前缀树中的单词,则剪枝,如果当前单词是前缀树中的单词,则将该单词加入答案,并将该单词在前缀树中的引用置为 ,表示该单词已经被找到,不需要再次搜索。
最后,我们将答案返回即可。
时间复杂度 ,空间复杂度 。其中 和 分别是 board 的行数和列数。而 和 分别是 words 中的单词的平均长度和单词的个数。
class Trie:
def __init__(self):
self.children: List[Trie | None] = [None] * 26
self.ref: int = -1
def insert(self, w: str, ref: int):
node = self
for c in w:
idx = ord(c) - ord('a')
if node.children[idx] is None:
node.children[idx] = Trie()
node = node.children[idx]
node.ref = ref
class Solution:
def findWords(self, board: List[List[str]], words: List[str]) -> List[str]:
def dfs(node: Trie, i: int, j: int):
idx = ord(board[i][j]) - ord('a')
if node.children[idx] is None:
return
node = node.children[idx]
if node.ref >= 0:
ans.append(words[node.ref])
node.ref = -1
c = board[i][j]
board[i][j] = '#'
for a, b in pairwise((-1, 0, 1, 0, -1)):
x, y = i + a, j + b
if 0 <= x < m and 0 <= y < n and board[x][y] != '#':
dfs(node, x, y)
board[i][j] = c
tree = Trie()
for i, w in enumerate(words):
tree.insert(w, i)
m, n = len(board), len(board[0])
ans = []
for i in range(m):
for j in range(n):
dfs(tree, i, j)
return ans
复杂度分析
| 指标 | 值 |
|---|---|
| 时间 | Depends on the final approach |
| 空间 | Depends on the final approach |
面试官常问的追问
外企场景- question_mark
The ability to optimize backtracking demonstrates an understanding of pruning and efficient search techniques.
- question_mark
Effective use of the Trie structure is a key indicator of solving this problem efficiently.
- question_mark
Understanding how to cut off unnecessary searches is critical for handling large test cases.
常见陷阱
外企场景- error
Not pruning the search early enough, leading to excessive recursion and time complexity.
- error
Forgetting to mark visited cells, which can cause revisiting and incorrect word formation.
- error
Using a brute-force approach without considering optimizations for large inputs.
进阶变体
外企场景- arrow_right_alt
Word Search III with multiple boards and word lists.
- arrow_right_alt
Word Search II on an NxM grid with varying path constraints.
- arrow_right_alt
Multi-level Word Search where the words are split across different sections of the board.