LeetCode 题解工作台
子树中标签相同的节点数
给你一棵树(即,一个连通的无环无向图),这棵树由编号从 0 到 n - 1 的 n 个节点组成,且恰好有 n - 1 条 edges 。树的根节点为节点 0 ,树上的每一个节点都有一个标签,也就是字符串 labels 中的一个小写字符(编号为 i 的 节点的标签就是 labels[i] ) 边数组 …
5
题型
5
代码语言
3
相关题
当前训练重点
中等 · 二分·树·traversal
答案摘要
我们先将边数组转换为邻接表 。 接下来我们从根节点 开始遍历其子树,过程中维护一个计数器 ,用于统计当前各个字母出现的次数。
Interview AiBoxInterview AiBox 实时 AI 助手,陪你讲清 二分·树·traversal 题型思路
题目描述
给你一棵树(即,一个连通的无环无向图),这棵树由编号从 0 到 n - 1 的 n 个节点组成,且恰好有 n - 1 条 edges 。树的根节点为节点 0 ,树上的每一个节点都有一个标签,也就是字符串 labels 中的一个小写字符(编号为 i 的 节点的标签就是 labels[i] )
边数组 edges 以 edges[i] = [ai, bi] 的形式给出,该格式表示节点 ai 和 bi 之间存在一条边。
返回一个大小为 n 的数组,其中 ans[i] 表示第 i 个节点的子树中与节点 i 标签相同的节点数。
树 T 中的子树是由 T 中的某个节点及其所有后代节点组成的树。
示例 1:
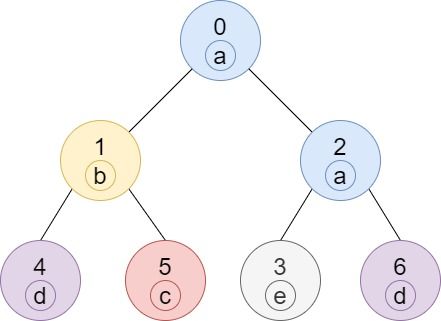
输入:n = 7, edges = [[0,1],[0,2],[1,4],[1,5],[2,3],[2,6]], labels = "abaedcd" 输出:[2,1,1,1,1,1,1] 解释:节点 0 的标签为 'a' ,以 'a' 为根节点的子树中,节点 2 的标签也是 'a' ,因此答案为 2 。注意树中的每个节点都是这棵子树的一部分。 节点 1 的标签为 'b' ,节点 1 的子树包含节点 1、4 和 5,但是节点 4、5 的标签与节点 1 不同,故而答案为 1(即,该节点本身)。
示例 2:
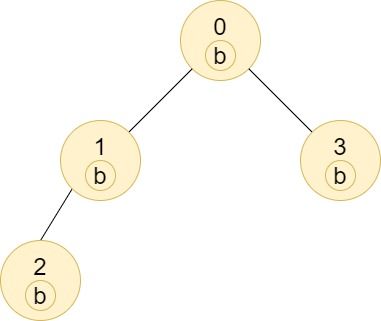
输入:n = 4, edges = [[0,1],[1,2],[0,3]], labels = "bbbb" 输出:[4,2,1,1] 解释:节点 2 的子树中只有节点 2 ,所以答案为 1 。 节点 3 的子树中只有节点 3 ,所以答案为 1 。 节点 1 的子树中包含节点 1 和 2 ,标签都是 'b' ,因此答案为 2 。 节点 0 的子树中包含节点 0、1、2 和 3,标签都是 'b',因此答案为 4 。
示例 3:
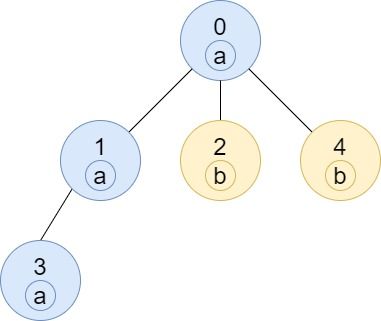
输入:n = 5, edges = [[0,1],[0,2],[1,3],[0,4]], labels = "aabab" 输出:[3,2,1,1,1]
提示:
1 <= n <= 10^5edges.length == n - 1edges[i].length == 20 <= ai, bi < nai != bilabels.length == nlabels仅由小写英文字母组成
解题思路
方法一:DFS
我们先将边数组转换为邻接表 。
接下来我们从根节点 开始遍历其子树,过程中维护一个计数器 ,用于统计当前各个字母出现的次数。
在访问某个节点 时,我们先将 减去 ,然后将 加 ,表示当前节点 的标签出现了一次。接下来递归访问其子节点,最后将 加上 。也即是说,我们将每个点离开时的计数器值减去每个点进来时的计数器值,就得到了以该点为根的子树中各个字母出现的次数。
时间复杂度 ,空间复杂度 。其中 为节点数;而 为字符集大小,本题中 。
class Solution:
def countSubTrees(self, n: int, edges: List[List[int]], labels: str) -> List[int]:
def dfs(i, fa):
ans[i] -= cnt[labels[i]]
cnt[labels[i]] += 1
for j in g[i]:
if j != fa:
dfs(j, i)
ans[i] += cnt[labels[i]]
g = defaultdict(list)
for a, b in edges:
g[a].append(b)
g[b].append(a)
cnt = Counter()
ans = [0] * n
dfs(0, -1)
return ans
复杂度分析
| 指标 | 值 |
|---|---|
| 时间 | complexity is O(n) because each node and edge is visited once during DFS. Space complexity is O(n * 26) due to hash tables tracking lowercase letters in each subtree. |
| 空间 | Depends on the final approach |
面试官常问的追问
外企场景- question_mark
DFS recursion with aggregation is expected rather than BFS.
- question_mark
Hash table usage for counting labels shows understanding of subtree state tracking.
- question_mark
Candidates should avoid global counters to prevent incorrect subtree counts.
常见陷阱
外企场景- error
Failing to include the current node in its own subtree count.
- error
Merging hash tables incorrectly, leading to undercounted labels.
- error
Revisiting nodes without a parent check, causing infinite recursion or double counting.
进阶变体
外企场景- arrow_right_alt
Count nodes in subtrees that match any of a set of target labels.
- arrow_right_alt
Compute subtree label counts in a tree with weighted edges affecting traversal.
- arrow_right_alt
Return not only counts but also lists of nodes per label in each subtree.