LeetCode 题解工作台
字符串中的查找与替换
你会得到一个字符串 s (索引从 0 开始),你必须对它执行 k 个替换操作。替换操作以三个长度均为 k 的并行数组给出: indices , sources , targets 。 要完成第 i 个替换操作: 检查 子字符串 sources[i] 是否出现在 原字符串 s 的索引 indices[…
4
题型
5
代码语言
3
相关题
当前训练重点
中等 · 数组·哈希·扫描
答案摘要
我们遍历每个替换操作,对于当前第 个替换操作 $(i, \text{src})$,如果 与 相等,此时我们记录下标 处需要替换的是 的第 个字符串,否则不需要替换。 接下来,我们只需要遍历原字符串 ,根据记录的信息进行替换即可。
Interview AiBoxInterview AiBox 实时 AI 助手,陪你讲清 数组·哈希·扫描 题型思路
题目描述
你会得到一个字符串 s (索引从 0 开始),你必须对它执行 k 个替换操作。替换操作以三个长度均为 k 的并行数组给出:indices, sources, targets。
要完成第 i 个替换操作:
- 检查 子字符串
sources[i]是否出现在 原字符串s的索引indices[i]处。 - 如果没有出现, 什么也不做 。
- 如果出现,则用
targets[i]替换 该子字符串。
例如,如果 s = "abcd" , indices[i] = 0 , sources[i] = "ab", targets[i] = "eee" ,那么替换的结果将是 "eeecd" 。
所有替换操作必须 同时 发生,这意味着替换操作不应该影响彼此的索引。测试用例保证元素间不会重叠 。
- 例如,一个
s = "abc",indices = [0,1],sources = ["ab","bc"]的测试用例将不会生成,因为"ab"和"bc"替换重叠。
在对 s 执行所有替换操作后返回 结果字符串 。
子字符串 是字符串中连续的字符序列。
示例 1:

输入:s = "abcd", indices = [0,2], sources = ["a","cd"], targets = ["eee","ffff"] 输出:"eeebffff" 解释: "a" 从 s 中的索引 0 开始,所以它被替换为 "eee"。 "cd" 从 s 中的索引 2 开始,所以它被替换为 "ffff"。
示例 2: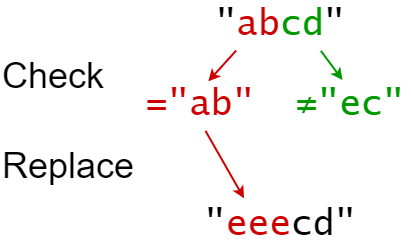
输入:s = "abcd", indices = [0,2], sources = ["ab","ec"], targets = ["eee","ffff"] 输出:"eeecd" 解释: "ab" 从 s 中的索引 0 开始,所以它被替换为 "eee"。 "ec" 没有从原始的 S 中的索引 2 开始,所以它没有被替换。
提示:
1 <= s.length <= 1000k == indices.length == sources.length == targets.length1 <= k <= 1000 <= indices[i] < s.length1 <= sources[i].length, targets[i].length <= 50s仅由小写英文字母组成sources[i]和targets[i]仅由小写英文字母组成
解题思路
方法一:模拟
我们遍历每个替换操作,对于当前第 个替换操作 ,如果 与 相等,此时我们记录下标 处需要替换的是 的第 个字符串,否则不需要替换。
接下来,我们只需要遍历原字符串 ,根据记录的信息进行替换即可。
时间复杂度 ,空间复杂度 。其中 是所有字符串的长度之和,而 是字符串 的长度。
class Solution:
def findReplaceString(
self, s: str, indices: List[int], sources: List[str], targets: List[str]
) -> str:
n = len(s)
d = [-1] * n
for k, (i, src) in enumerate(zip(indices, sources)):
if s.startswith(src, i):
d[i] = k
ans = []
i = 0
while i < n:
if ~d[i]:
ans.append(targets[d[i]])
i += len(sources[d[i]])
else:
ans.append(s[i])
i += 1
return "".join(ans)
复杂度分析
| 指标 | 值 |
|---|---|
| 时间 | complexity: O(k * m), where k is the number of replacement operations and m is the average length of the source strings. This comes from checking each source string for a match at the given index. Space complexity: O(n), where n is the length of the string s, as we create a new string after performing all replacements. |
| 空间 | Depends on the final approach |
面试官常问的追问
外企场景- question_mark
Look for understanding of how to apply array scanning and hash lookup techniques for string modifications.
- question_mark
Assess how well the candidate handles edge cases where no replacements occur or where an index does not match.
- question_mark
Check for knowledge of optimizing string modifications, avoiding repeated concatenation within loops.
常见陷阱
外企场景- error
Not checking if the source matches the substring before applying the replacement.
- error
Modifying the string in place in an inefficient way, leading to unnecessary overhead.
- error
Failing to handle cases where the source does not match the substring at a given index.
进阶变体
外企场景- arrow_right_alt
Using a hash map for faster lookups when there are many replacement operations.
- arrow_right_alt
Implementing the function with a greedy approach where you prioritize larger replacements first.
- arrow_right_alt
Performing all replacements in one pass through the string using a more advanced string manipulation algorithm.