LeetCode 题解工作台
每棵子树内缺失的最小基因值
有一棵根节点为 0 的 家族树 ,总共包含 n 个节点,节点编号为 0 到 n - 1 。给你一个下标从 0 开始的整数数组 parents ,其中 parents[i] 是节点 i 的父节点。由于节点 0 是 根 ,所以 parents[0] == -1 。 总共有 10 5 个基因值,每个基因值…
4
题型
6
代码语言
3
相关题
当前训练重点
困难 · 二分·树·traversal
答案摘要
我们注意到,每个节点的基因值互不相同,因此,我们只需要找到基因值为 的节点 ,那么除了从节点 到根节点 的每个节点,其它节点的答案都是 。 因此,我们初始化答案数组 为 ,然后我们的重点就在于求出节点 到根节点 的路径上的每个节点的答案。
Interview AiBoxInterview AiBox 实时 AI 助手,陪你讲清 二分·树·traversal 题型思路
题目描述
有一棵根节点为 0 的 家族树 ,总共包含 n 个节点,节点编号为 0 到 n - 1 。给你一个下标从 0 开始的整数数组 parents ,其中 parents[i] 是节点 i 的父节点。由于节点 0 是 根 ,所以 parents[0] == -1 。
总共有 105 个基因值,每个基因值都用 闭区间 [1, 105] 中的一个整数表示。给你一个下标从 0 开始的整数数组 nums ,其中 nums[i] 是节点 i 的基因值,且基因值 互不相同 。
请你返回一个数组 ans ,长度为 n ,其中 ans[i] 是以节点 i 为根的子树内 缺失 的 最小 基因值。
节点 x 为根的 子树 包含节点 x 和它所有的 后代 节点。
示例 1:
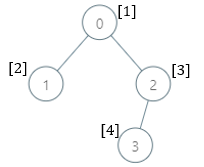
输入:parents = [-1,0,0,2], nums = [1,2,3,4] 输出:[5,1,1,1] 解释:每个子树答案计算结果如下: - 0:子树包含节点 [0,1,2,3] ,基因值分别为 [1,2,3,4] 。5 是缺失的最小基因值。 - 1:子树只包含节点 1 ,基因值为 2 。1 是缺失的最小基因值。 - 2:子树包含节点 [2,3] ,基因值分别为 [3,4] 。1 是缺失的最小基因值。 - 3:子树只包含节点 3 ,基因值为 4 。1是缺失的最小基因值。
示例 2:
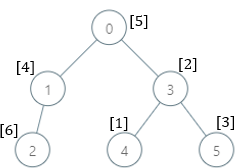
输入:parents = [-1,0,1,0,3,3], nums = [5,4,6,2,1,3] 输出:[7,1,1,4,2,1] 解释:每个子树答案计算结果如下: - 0:子树内包含节点 [0,1,2,3,4,5] ,基因值分别为 [5,4,6,2,1,3] 。7 是缺失的最小基因值。 - 1:子树内包含节点 [1,2] ,基因值分别为 [4,6] 。 1 是缺失的最小基因值。 - 2:子树内只包含节点 2 ,基因值为 6 。1 是缺失的最小基因值。 - 3:子树内包含节点 [3,4,5] ,基因值分别为 [2,1,3] 。4 是缺失的最小基因值。 - 4:子树内只包含节点 4 ,基因值为 1 。2 是缺失的最小基因值。 - 5:子树内只包含节点 5 ,基因值为 3 。1 是缺失的最小基因值。
示例 3:
输入:parents = [-1,2,3,0,2,4,1], nums = [2,3,4,5,6,7,8] 输出:[1,1,1,1,1,1,1] 解释:所有子树都缺失基因值 1 。
提示:
n == parents.length == nums.length2 <= n <= 105- 对于
i != 0,满足0 <= parents[i] <= n - 1 parents[0] == -1parents表示一棵合法的树。1 <= nums[i] <= 105nums[i]互不相同。
解题思路
方法一:DFS
我们注意到,每个节点的基因值互不相同,因此,我们只需要找到基因值为 的节点 ,那么除了从节点 到根节点 的每个节点,其它节点的答案都是 。
因此,我们初始化答案数组 为 ,然后我们的重点就在于求出节点 到根节点 的路径上的每个节点的答案。
我们可以从节点 开始,通过深度优先搜索的方式,标记以 作为根节点的子树中出现过的基因值,记录在数组 中。搜索过程中,我们用一个数组 标记已经访问过的节点,防止重复访问。
接下来,我们从 开始,不断向后寻找第一个没有出现过的基因值,即为节点 的答案。这里 是严格递增的,因为基因值互不相同,所以我们一定能在 中找到一个没有出现过的基因值。
然后,我们更新节点 的答案,即 ,并将 更新为其父节点,继续上述过程,直到 ,即到达了根节点 。
最后,我们返回答案数组 即可。
时间复杂度 ,空间复杂度 。其中 是节点的数量。
class Solution:
def smallestMissingValueSubtree(
self, parents: List[int], nums: List[int]
) -> List[int]:
def dfs(i: int):
if vis[i]:
return
vis[i] = True
if nums[i] < len(has):
has[nums[i]] = True
for j in g[i]:
dfs(j)
n = len(nums)
ans = [1] * n
g = [[] for _ in range(n)]
idx = -1
for i, p in enumerate(parents):
if i:
g[p].append(i)
if nums[i] == 1:
idx = i
if idx == -1:
return ans
vis = [False] * n
has = [False] * (n + 2)
i = 2
while idx != -1:
dfs(idx)
while has[i]:
i += 1
ans[idx] = i
idx = parents[idx]
return ans
复杂度分析
| 指标 | 值 |
|---|---|
| 时间 | complexity depends on the DFS traversal and merging strategy; naive merging is O(n^2) but optimized union-by-size approaches reduce it near O(n). Space complexity is proportional to the number of nodes and distinct genetic values in the largest subtree. |
| 空间 | Depends on the final approach |
面试官常问的追问
外企场景- question_mark
Ask about handling missing value propagation efficiently across subtrees.
- question_mark
Expect discussion on how to optimize set merging for large trees.
- question_mark
Look for recognizing that missing value 1 can be directly returned when absent from a subtree.
常见陷阱
外企场景- error
Merging child sets without optimizing leads to TLE for large n.
- error
Assuming missing values propagate sequentially without checking each subtree's minimal value.
- error
Ignoring the special case when 1 is missing, causing incorrect results in many leaf subtrees.
进阶变体
外企场景- arrow_right_alt
Find the largest missing genetic value in each subtree instead of the smallest.
- arrow_right_alt
Compute the sum of all missing genetic values in each subtree.
- arrow_right_alt
Determine missing genetic values for arbitrary subtrees queried multiple times dynamically.