LeetCode 题解工作台
边权重均等查询
现有一棵由 n 个节点组成的无向树,节点按从 0 到 n - 1 编号。给你一个整数 n 和一个长度为 n - 1 的二维整数数组 edges ,其中 edges[i] = [u i , v i , w i ] 表示树中存在一条位于节点 u i 和节点 v i 之间、权重为 w i 的边。 另给你一…
4
题型
4
代码语言
3
相关题
当前训练重点
困难 · 二分·树·traversal
答案摘要
题目求的是任意两点的路径上,将其所有边的权重变成相同值的最小操作次数。实际上就是求这两点之间的路径长度,减去路径上出现次数最多的边的次数。 而求两点间的路径长度,可以通过倍增法求 LCA 来实现。我们记两点分别为 和 ,最近公共祖先为 ,那么 到 的路径长度就是 $depth(u) + depth(v) - 2 \times depth(x)$。
Interview AiBoxInterview AiBox 实时 AI 助手,陪你讲清 二分·树·traversal 题型思路
题目描述
现有一棵由 n 个节点组成的无向树,节点按从 0 到 n - 1 编号。给你一个整数 n 和一个长度为 n - 1 的二维整数数组 edges ,其中 edges[i] = [ui, vi, wi] 表示树中存在一条位于节点 ui 和节点 vi 之间、权重为 wi 的边。
另给你一个长度为 m 的二维整数数组 queries ,其中 queries[i] = [ai, bi] 。对于每条查询,请你找出使从 ai 到 bi 路径上每条边的权重相等所需的 最小操作次数 。在一次操作中,你可以选择树上的任意一条边,并将其权重更改为任意值。
注意:
- 查询之间 相互独立 的,这意味着每条新的查询时,树都会回到 初始状态 。
- 从
ai到bi的路径是一个由 不同 节点组成的序列,从节点ai开始,到节点bi结束,且序列中相邻的两个节点在树中共享一条边。
返回一个长度为 m 的数组 answer ,其中 answer[i] 是第 i 条查询的答案。
示例 1:
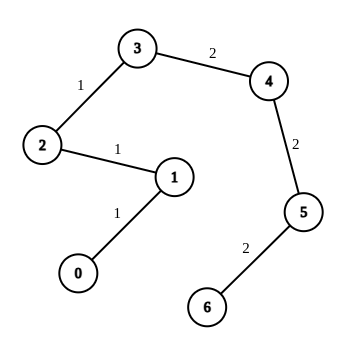
输入:n = 7, edges = [[0,1,1],[1,2,1],[2,3,1],[3,4,2],[4,5,2],[5,6,2]], queries = [[0,3],[3,6],[2,6],[0,6]] 输出:[0,0,1,3] 解释:第 1 条查询,从节点 0 到节点 3 的路径中的所有边的权重都是 1 。因此,答案为 0 。 第 2 条查询,从节点 3 到节点 6 的路径中的所有边的权重都是 2 。因此,答案为 0 。 第 3 条查询,将边 [2,3] 的权重变更为 2 。在这次操作之后,从节点 2 到节点 6 的路径中的所有边的权重都是 2 。因此,答案为 1 。 第 4 条查询,将边 [0,1]、[1,2]、[2,3] 的权重变更为 2 。在这次操作之后,从节点 0 到节点 6 的路径中的所有边的权重都是 2 。因此,答案为 3 。 对于每条查询 queries[i] ,可以证明 answer[i] 是使从 ai 到 bi 的路径中的所有边的权重相等的最小操作次数。
示例 2:
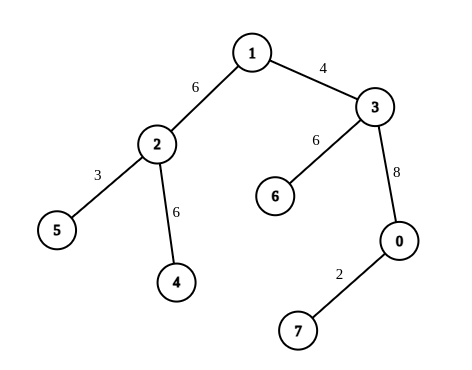
输入:n = 8, edges = [[1,2,6],[1,3,4],[2,4,6],[2,5,3],[3,6,6],[3,0,8],[7,0,2]], queries = [[4,6],[0,4],[6,5],[7,4]] 输出:[1,2,2,3] 解释:第 1 条查询,将边 [1,3] 的权重变更为 6 。在这次操作之后,从节点 4 到节点 6 的路径中的所有边的权重都是 6 。因此,答案为 1 。 第 2 条查询,将边 [0,3]、[3,1] 的权重变更为 6 。在这次操作之后,从节点 0 到节点 4 的路径中的所有边的权重都是 6 。因此,答案为 2 。 第 3 条查询,将边 [1,3]、[5,2] 的权重变更为 6 。在这次操作之后,从节点 6 到节点 5 的路径中的所有边的权重都是 6 。因此,答案为 2 。 第 4 条查询,将边 [0,7]、[0,3]、[1,3] 的权重变更为 6 。在这次操作之后,从节点 7 到节点 4 的路径中的所有边的权重都是 6 。因此,答案为 3 。 对于每条查询 queries[i] ,可以证明 answer[i] 是使从 ai 到 bi 的路径中的所有边的权重相等的最小操作次数。
提示:
1 <= n <= 104edges.length == n - 1edges[i].length == 30 <= ui, vi < n1 <= wi <= 26- 生成的输入满足
edges表示一棵有效的树 1 <= queries.length == m <= 2 * 104queries[i].length == 20 <= ai, bi < n
解题思路
方法一:倍增法求 LCA
题目求的是任意两点的路径上,将其所有边的权重变成相同值的最小操作次数。实际上就是求这两点之间的路径长度,减去路径上出现次数最多的边的次数。
而求两点间的路径长度,可以通过倍增法求 LCA 来实现。我们记两点分别为 和 ,最近公共祖先为 ,那么 到 的路径长度就是 。
另外,我们可以用一个数组 记录根节点到每个节点上,每个边权重出现的次数。那么 到 的路径上,出现次数最多的边的次数就是 。其中 为 和 的最近公共祖先。
倍增法求 LCA 的过程如下:
我们记每个节点的深度为 ,父节点为 ,而 表示节点 的第 个祖先。那么,对于任意两点 和 ,我们可以通过以下方式求出它们的最近公共祖先:
- 如果 ,那么交换 和 ,即保证 的深度不小于 的深度;
- 接下来,我们将 的深度不断向上提升,直到 和 的深度相同,此时 和 的深度都为 ;
- 然后,我们将 和 的深度同时向上提升,直到 和 的父节点相同,此时 和 的父节点都为 ,即为 和 的最近公共祖先。
最后,节点 到节点 的最小操作次数就是 。
时间复杂度 ,空间复杂度 ,其中 为边权重的最大值。
class Solution:
def minOperationsQueries(
self, n: int, edges: List[List[int]], queries: List[List[int]]
) -> List[int]:
m = n.bit_length()
g = [[] for _ in range(n)]
f = [[0] * m for _ in range(n)]
p = [0] * n
cnt = [None] * n
depth = [0] * n
for u, v, w in edges:
g[u].append((v, w - 1))
g[v].append((u, w - 1))
cnt[0] = [0] * 26
q = deque([0])
while q:
i = q.popleft()
f[i][0] = p[i]
for j in range(1, m):
f[i][j] = f[f[i][j - 1]][j - 1]
for j, w in g[i]:
if j != p[i]:
p[j] = i
cnt[j] = cnt[i][:]
cnt[j][w] += 1
depth[j] = depth[i] + 1
q.append(j)
ans = []
for u, v in queries:
x, y = u, v
if depth[x] < depth[y]:
x, y = y, x
for j in reversed(range(m)):
if depth[x] - depth[y] >= (1 << j):
x = f[x][j]
for j in reversed(range(m)):
if f[x][j] != f[y][j]:
x, y = f[x][j], f[y][j]
if x != y:
x = p[x]
mx = max(cnt[u][j] + cnt[v][j] - 2 * cnt[x][j] for j in range(26))
ans.append(depth[u] + depth[v] - 2 * depth[x] - mx)
return ans
复杂度分析
| 指标 | 值 |
|---|---|
| 时间 | Depends on the final approach |
| 空间 | Depends on the final approach |
面试官常问的追问
外企场景- question_mark
The candidate should demonstrate a clear understanding of tree traversal techniques and path compression.
- question_mark
Look for the ability to optimize query handling and precompute useful data during tree traversal.
- question_mark
The candidate should be able to discuss the trade-offs between preprocessing and query handling in large datasets.
常见陷阱
外企场景- error
Failing to optimize for large numbers of queries by neglecting path compression or efficient data handling.
- error
Overcomplicating the problem by not leveraging tree properties or by using brute force for path queries.
- error
Incorrectly calculating the minimum number of operations needed due to misunderstandings about the path and weight frequency tracking.
进阶变体
外企场景- arrow_right_alt
Consider cases with more complex tree structures, like binary search trees or trees with high depth.
- arrow_right_alt
How would the approach change if the edges had weights beyond the simple range of 1-26?
- arrow_right_alt
What optimizations can be made if the tree has additional constraints such as a high number of queries relative to nodes?