LeetCode 题解工作台
统计 X 和 Y 频数相等的子矩阵数量
给你一个二维字符矩阵 grid ,其中 grid[i][j] 可能是 'X' 、 'Y' 或 '.' ,返回满足以下条件的 子矩阵 数量: 包含 grid[0][0] 'X' 和 'Y' 的频数相等。 至少包含一个 'X' 。 示例 1: 输入: grid = [["X","Y","."],["Y"…
3
题型
6
代码语言
3
相关题
当前训练重点
中等 · 数组·matrix
答案摘要
根据题目描述,我们只需要统计每个位置 $(i, j)$ 的前缀和 和 ,分别表示从 $(0, 0)$ 到 $(i, j)$ 的子矩阵中字符 `X` 和 `Y` 的数量,如果 $s[i][j][0] > 0$ 且 $s[i][j][0] = s[i][j][1]$,则说明满足题目条件,答案加一。 遍历完所有位置后,返回答案即可。
Interview AiBoxInterview AiBox 实时 AI 助手,陪你讲清 数组·matrix 题型思路
题目描述
给你一个二维字符矩阵 grid,其中 grid[i][j] 可能是 'X'、'Y' 或 '.',返回满足以下条件的子矩阵数量:
- 包含
grid[0][0] 'X'和'Y'的频数相等。- 至少包含一个
'X'。
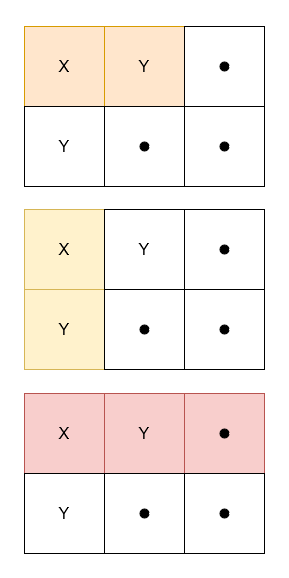
示例 1:
输入: grid = [["X","Y","."],["Y",".","."]]
输出: 3
解释:
示例 2:
输入: grid = [["X","X"],["X","Y"]]
输出: 0
解释:
不存在满足 'X' 和 'Y' 频数相等的子矩阵。
示例 3:
输入: grid = [[".","."],[".","."]]
输出: 0
解释:
不存在满足至少包含一个 'X' 的子矩阵。
提示:
1 <= grid.length, grid[i].length <= 1000grid[i][j]可能是'X'、'Y'或'.'.
解题思路
方法一:二维前缀和
根据题目描述,我们只需要统计每个位置 的前缀和 和 ,分别表示从 到 的子矩阵中字符 X 和 Y 的数量,如果 且 ,则说明满足题目条件,答案加一。
遍历完所有位置后,返回答案即可。
时间复杂度 ,空间复杂度 。其中 和 分别表示矩阵的行数和列数。
class Solution:
def numberOfSubmatrices(self, grid: List[List[str]]) -> int:
m, n = len(grid), len(grid[0])
s = [[[0] * 2 for _ in range(n + 1)] for _ in range(m + 1)]
ans = 0
for i, row in enumerate(grid, 1):
for j, x in enumerate(row, 1):
s[i][j][0] = s[i - 1][j][0] + s[i][j - 1][0] - s[i - 1][j - 1][0]
s[i][j][1] = s[i - 1][j][1] + s[i][j - 1][1] - s[i - 1][j - 1][1]
if x != ".":
s[i][j][ord(x) & 1] += 1
if s[i][j][0] > 0 and s[i][j][0] == s[i][j][1]:
ans += 1
return ans
复杂度分析
| 指标 | 值 |
|---|---|
| 时间 | Depends on the final approach |
| 空间 | Depends on the final approach |
面试官常问的追问
外企场景- question_mark
Check for a transformation approach involving numerical mapping of 'X', 'Y', and '.' to facilitate zero-sum subarray counting.
- question_mark
Look for efficient usage of prefix sums to avoid brute-force submatrix enumeration.
- question_mark
Ensure that the candidate identifies and handles edge cases such as grids with only '.' or one type of character.
常见陷阱
外企场景- error
Using brute force to check every possible submatrix will result in a time complexity that is too high for larger grids.
- error
Forgetting to transform the grid correctly, which can lead to incorrect results when checking submatrices.
- error
Not properly handling edge cases such as grids with no 'X' or 'Y' characters, which can cause miscounts.
进阶变体
外企场景- arrow_right_alt
What if the grid size is fixed, say 10x10? Can you optimize for this case?
- arrow_right_alt
What happens if the grid contains additional characters, such as 'A' or 'Z'? How would you adjust the approach?
- arrow_right_alt
How would you adapt the solution if instead of equal counts of 'X' and 'Y', you needed a specific ratio of 'X' to 'Y'?